


Le traitement des données aux CFL, c’est tout un sujet. C’est notamment ce à quoi se consacrent Thibaut et son collègue Thierry, au sein de l’équipe Datahub. Rencontre.
Bonjour Thibaut, tu as 27 ans et tu es analyste programmeur Business Intelligence dans l’équipe Datahub depuis maintenant 3 ans : si tu commençais par nous expliquer ce qu’est la Business Intelligence ?
La Business Intelligence, abrégée « BI », désigne un processus technologique de traitement et d’analyse de données qui a pour but de présenter des informations utiles et compréhensibles par l’utilisateur final en vue d’en tirer une connaissance pour l’Entreprise et ses collaborateurs.
C’est un peu comme une boite à outils de la donnée permettant à toute personne ayant un besoin d’être capable de prendre des décisions et actions rapides sur base des visuels et statistiques qui lui sont mis à disposition.
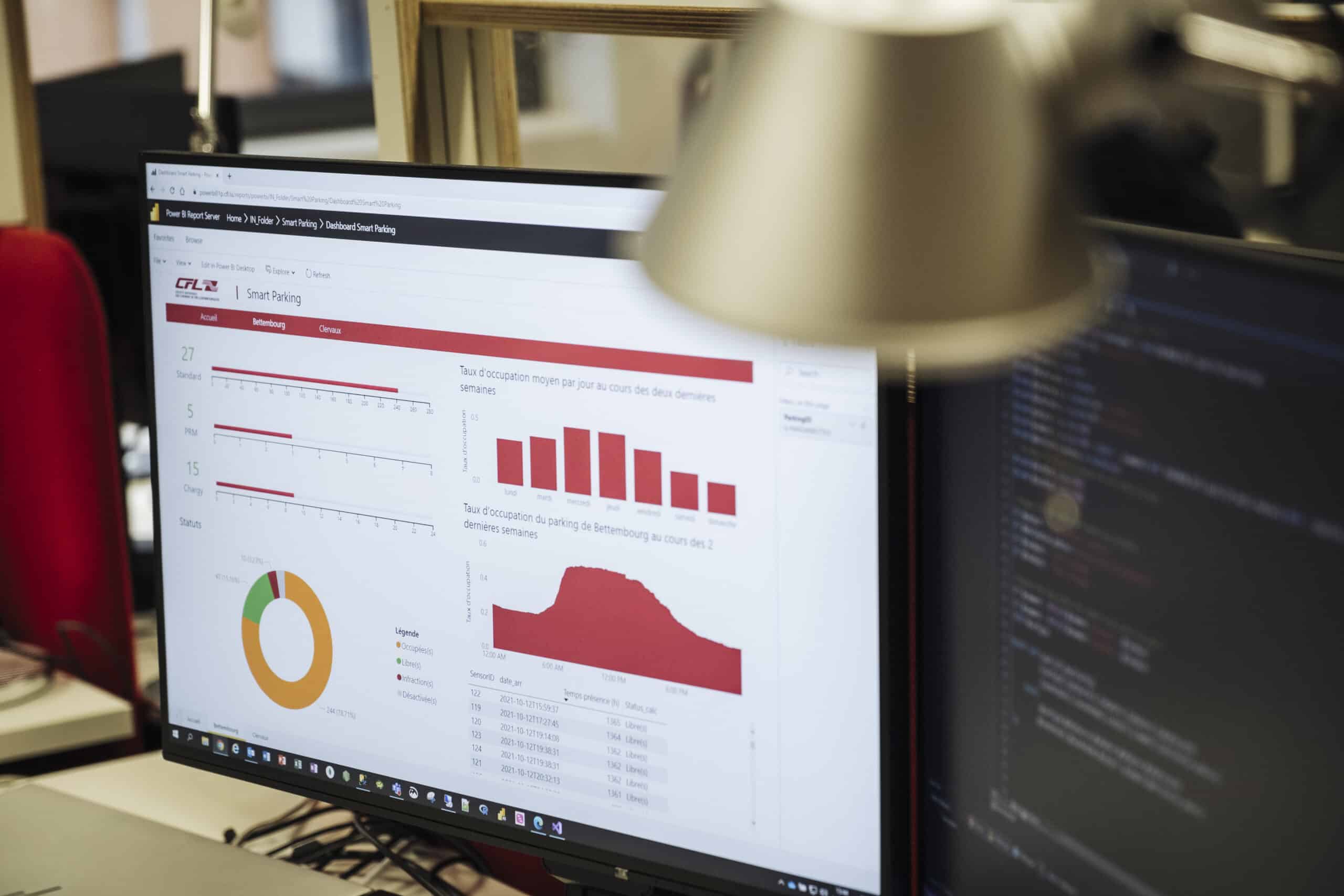
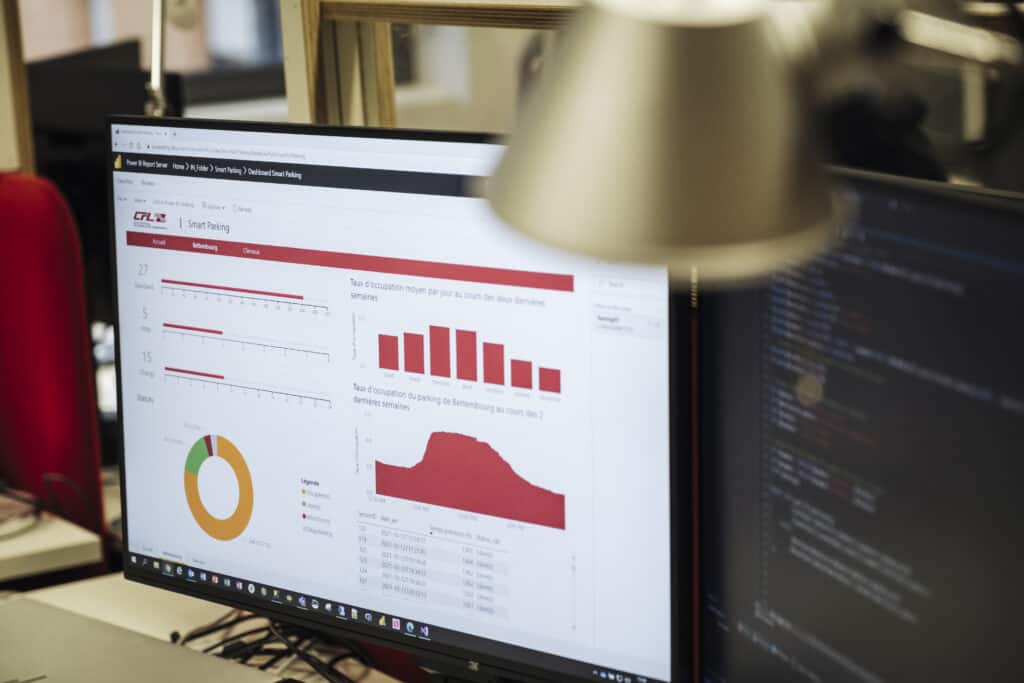
Imaginons que l’on détecte qu’un parking dispose d’un certain nombre de places inoccupées alors qu’il devrait être complet. Avec les outils de BI, on va pouvoir détecter cela et envoyer quelqu’un pour comprendre pourquoi ces places sont inoccupées (travaux, encombrements, etc.).
Encore une petite explication pour nous aider à comprendre : Datahub, donnée, big data… c’est quoi la différence ?
Le « hub » de Datahub indique un lieu de passage si on veut, c’est par notre service que transitent les données de l’entreprise, ou « la donnée ». La donnée, data en anglais, c’est un élément d’information brut qui peut être structuré (fichier excel, base de données, etc.) ou non structuré (image, son, etc.), qui ne peut pas être exploité ou compris sans contexte. Enfin, le Big Data, ça désigne l’ensemble de toutes les données collectées par les entreprises, indépendamment de tout traitement. Le Big Data est un sujet à part entière dans notre société de l’information : nous générons des données de plus en plus variées, dans des volumes de plus en plus importants, à une vitesse toujours plus élevée. La vraie valeur ajoutée pour les entreprises est de faire de cette masse de données de l’information utile. C’est là toute la mission de notre équipe Datahub : nous mettons en place une solution qui est capable de gérer un large flux de données, qui les transforme en informations et en connaissances utiles (en les croisant entre elles par exemple) et en les rendant accessibles et exploitables par les services qui en ont besoin.
Dans l’équipe Datahub, peux-tu nous expliquer en quoi consiste précisément ta mission ?
En tant qu’analyste programmeur BI mon rôle principal est de définir et développer des solutions qui vont transformer de la donnée brute, issue de systèmes d’information ou de capteurs en semi temps réel et/ou temps réel, en de l’information qui soit utile et claire pour le métier. Je vais mettre à disposition des rapports ou « tableaux de bord » pour les services, qui vont leur permettre d’accéder aux informations, et de mieux les interpréter, en les recoupant par exemple avec d’autres éléments, je vais vous donner un exemple plus tard.
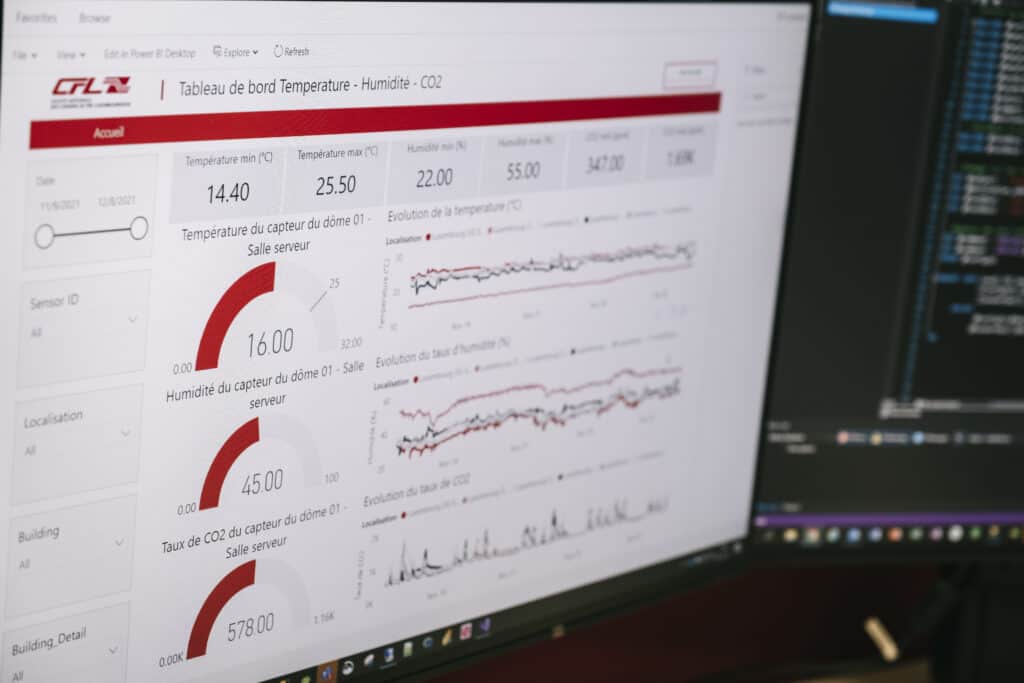
Depuis 2 ans, nous nous concentrons également sur une nouvelle technologie qui permet de traiter de la donnée brute en temps réel cette fois. Pour ça, on travaille avec l’équipe Internet Of Things pour construire des flux opérationnels qui récupèrent les données des capteurs qu’ils ont installés (dans des locaux, à bord du matériel roulant, sur les rails…) et qui en tirent de l’information grâce à un processus automatisé.

Comment sont conçus ces rapports ?
Les rapports sont conçus à partir des besoins des utilisateurs : nous identifions dans un premier temps les sources (internes ou externes) qui nous fourniront les données.
S’il faut se connecter à un système externe pour récupérer les données, nous allons faire intervenir l’équipe sécurité informatique pour nous assurer du niveau de confidentialité des flux. Comme dans tout aux CFL, la sécurité est la priorité absolue.
Pour les données collectées en interne, il peut aussi arriver que ce soit des données que l’on ne collecte pas encore, et il faut alors établir comment les collecter. Dernièrement, ça passe beaucoup par l’équipe IoT et les capteurs qu’elle va alors installer pour répondre à ce besoin de collecte.
Une fois que la communication entre toutes nos sources de données et notre outil de Business intelligence est opérationnelle, nous analysons ensuite comment présenter les données, ou les croiser entre elles pour qu’elles deviennent des informations utiles à l’utilisateur.
Pour les utilisateurs, il s’agit concrètement d’aller sur internet et de se connecter à leur environnement de travail numérique pour accéder à leur rapport, c’est très simple. L’information est présentée de manière très visuelle avec des tableaux, des graphiques, des histogrammes, reprenant différents critères qu’ils peuvent ajuster à loisir.

Nous avons rencontré Elisa de l’équipe IoT il y a quelques mois, et elle nous a parlé du parking intelligent de Bettembourg. Elle a été chargée de trouver le bon type de capteur pour détecter la présence des voitures sur le parking. De ton côté, en quoi consiste ce projet ?
Dès lors que l’équipe d’Elisa avait trouvé le bon type de capteur et avait vérifié qu’il communiquait bien avec notre plateforme, j’ai pris le relais pour mettre en place un flux informatisé qui récupère ces données, les convertisse au format voulu et les stocke dans nos bases de données. À l’aide d’une autre équipe du service informatique, nous avons extrait les données pour les mettre à disposition des utilisateurs en interne. La finalité de ce projet est de fournir aux usagers du train une information en temps réel sur le nombre de places disponibles, afin qu’ils puissent planifier au mieux leurs déplacements. Dans un futur pas si lointain, notre ambition est de pouvoir anticiper avec précision les mouvements sur le parking, toujours dans une optique de service au client. Pour cela, nous nous appuierons sur l’historique des mouvements constatés pour construire un modèle prédictif. Sur base des infos reçues en temps réel, nous pourrons alors anticiper le taux d’occupation du parking dans les heures qui suivent.
Ça va prendre encore un peu de temps, car ça demande une expertise très pointue en terme de choix du modèle mathématique à privilégier dans cette approche, et nous nous faisons aider d’un cabinet externe pour avancer, mais l’idée est de recruter des profils compétents pour renforcer l’équipe à moyen terme.

Tu viens de citer le service au client, comme moteur dans ce projet de parking intelligent, as-tu un autre exemple impactant pour le client dans les sujets qui vous occupent actuellement au Datahub ?
Nous n’avons pas d’impact direct sur la circulation des trains, mais nous pouvons fournir des données qui en ont. Par exemple, les données de comptage des voyageurs dans les trains permettent d’adapter l’offre en fonction de la fréquentation réelle des transports.
Ce comptage s’appuie sur les données remontées par des capteurs installés aux portes extérieures et intérieures des trains, et envoie les données en temps réel au système. On connaît déjà actuellement en temps réel le nombre de passagers pour un train donné, combien descendent et montent dans les différentes gares sur le parcours. En poussant davantage notre usage, nous pourrons indiquer aux voyageurs sur le quai à quel endroit monter dans le train pour s’assurer une place assise, ce qui pourra impacter positivement leur expérience de transport.
En poussant davantage notre usage, nous pourrons indiquer aux voyageurs sur le quai à quel endroit monter dans le train pour s’assurer une place assise, ce qui pourra impacter positivement leur expérience de transport.

Un autre projet influera sur la fiabilité de nos trains, et donc sur la satisfaction des voyageurs : il est prévu de récupérer de nombreuses données liées au matériel roulant (état des freins, moteurs, température…) pour intégrer des principes de « machine learning » et anticiper plus efficacement les maintenances et éviter des avaries. Ceci va réduire la durée d’immobilisation de notre matériel et éviter des pannes lourdes qui sont généralement synonymes de retard ou d’annulation.

Donc si je te comprends bien quand tu parles de « machine learning », on collecte les données pendant un certain moment, et on analyse en parallèle le vieillissement et le comportement du matériel ?
Tout à fait ! Actuellement, les plans de maintenance du matériel roulant sont basés sur des cycles de X semaines. Grâce au machine learning, on planifierait alors sur base de l’état réel du matériel, ce qui serait beaucoup plus efficace et augmenterait sensiblement notre fiabilité.
Le plus gros challenge pour nous est de fournir des informations fiables et pertinentes à tout moment, car les attentes vont s’élever naturellement en interne et en externe : à nous d’être à la hauteur.
Dans 10 ans, à quoi ressemblera ton métier ?
Aucune idée ! Les technologies évoluent tellement vite que c’est impossible à dire. Pour l’instant on est sûr de la statistique pure, on glisse doucement vers de l’analyse prédictive de données, et ce sera ensuite assez logiquement de l’analyse prescriptive d’ici 3 à 5 ans, mais ensuite… ?
Je ne sais pas à quoi ressemblera mon métier dans 10 ans, mais je sais que je continuerai à l’orienter de façon à ce que les transports en commun, combinés aux transports partagés – les vélos de la ville ou les voitures Flex par exemple – s’imposent naturellement face aux voitures individuelles, il y a un réel enjeu environnemental sur cette question.
… je continuerai à l’orienter de façon à ce que les transports en commun, combinés aux transports partagés (…) s’imposent naturellement face aux voitures individuelles, il y a un réel enjeu environnemental sur cette question.

Si comme Thibaut, vous voulez suivre le tempo de la digitalisation en donnant du sens à votre carrière, rejoignez les CFL : nous recrutons.


Comments are closed.