


Die Datenverarbeitung bei der CFL ist ein wichtiges Thema. Und genau das ist es, womit sich Thibaut und sein Kollege Thierry im Datahub-Team beschäftigen. Eine spannende Begegnung:
Hallo Thibaut, du bist 27 Jahre alt und seit nunmehr drei Jahren Programmanalytiker für Business Intelligence im Datahub-Team: Wie wäre es, wenn du uns zunächst einmal erklärst, was Business Intelligence ist?
Business Intelligence, abgekürzt „BI“, bezeichnet einen technologischen Prozess der Datenverarbeitung und -analyse, dessen Ziel es ist, nützliche und für den Endbenutzer verständliche Informationen zu präsentieren, um daraus Wissen für das Unternehmen und seine Mitarbeiter zu gewinnen.
Es ist so etwas wie ein Daten-Werkzeugkasten, der es jedem, der einen Bedarf hat, ermöglicht, auf der Grundlage der ihm zur Verfügung gestellten Visualisierungen und Statistiken schnelle Entscheidungen und Handlungen zu treffen.
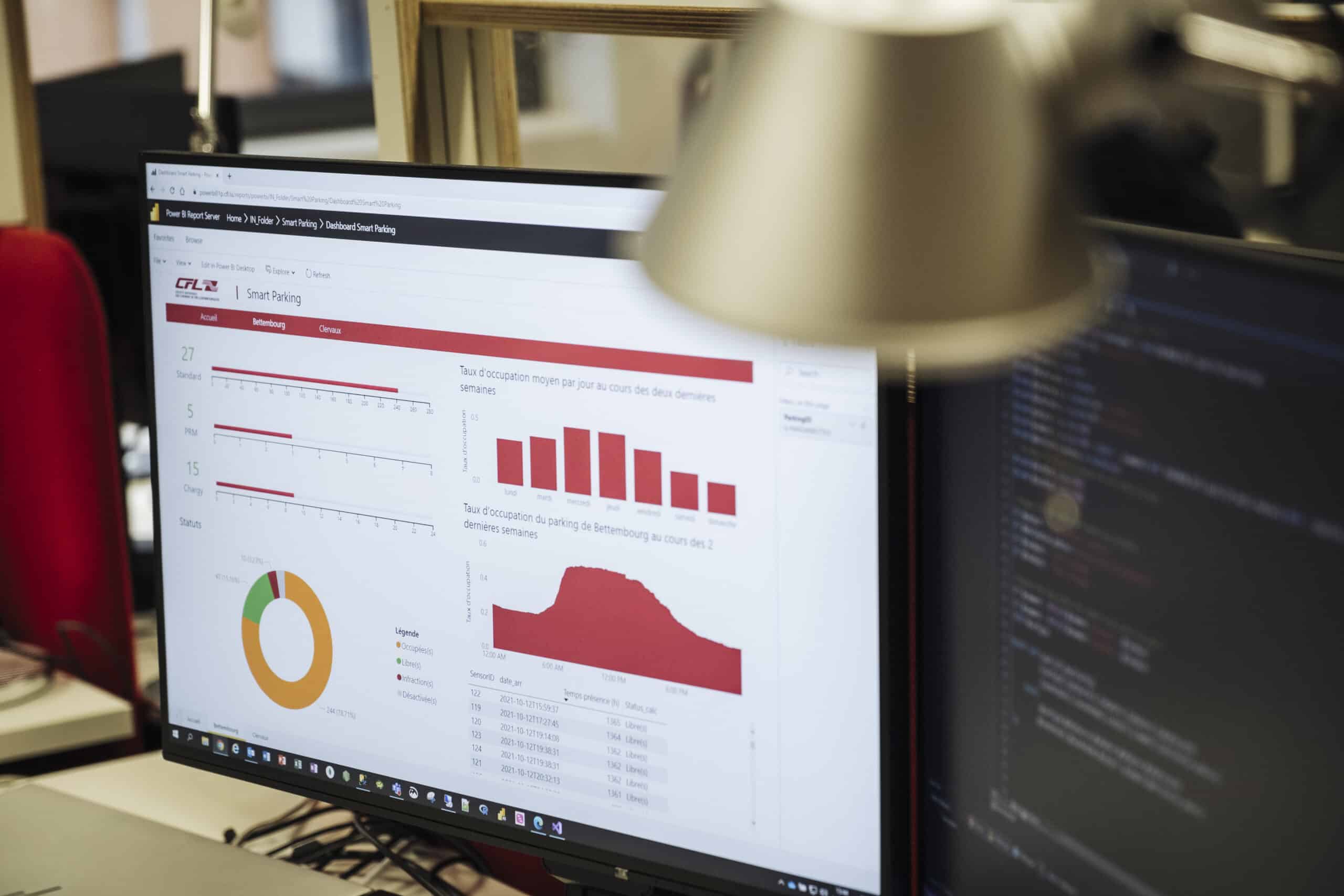
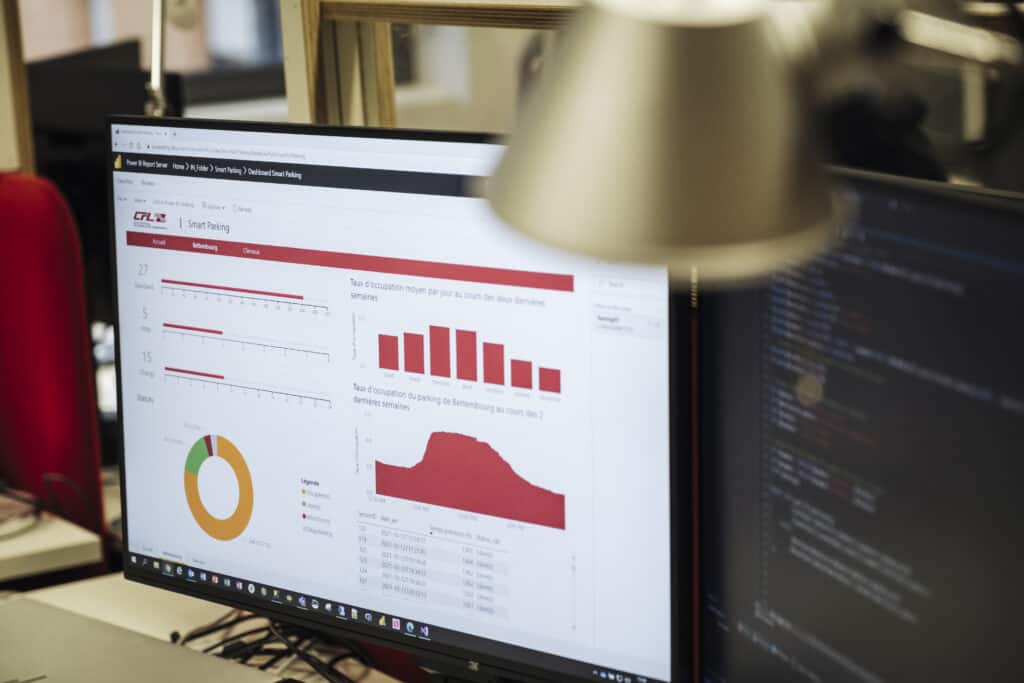
Angenommen, man stellt fest, dass ein Parkplatz eine bestimmte Anzahl unbesetzter Plätze hat, obwohl er voll belegt sein sollte. Mithilfe von BI-Tools wird man dies erkennen und jemanden losschicken können, um herauszufinden, warum diese Plätze unbesetzt sind (Baustellen, Staus usw.).
Vielleicht noch eine kleine Begriffserklärung, damit wir es besser verstehen: Datahub, Daten, Big Data … wo liegt eigentlich der Unterschied?
Der „Hub“ von Datahub bezeichnet sozusagen einen Durchgangsort, und es ist unsere Abteilung, durch die die Daten des Unternehmens oder „die Daten“ fließen. Die Daten, data auf Englisch, sind ein rohes Informationselement, das strukturiert (Excel-Datei, Datenbank usw.) oder unstrukturiert (Bild, Ton usw.) sein kann, und das ohne Kontext nicht ausgewertet oder verstanden werden kann. Big Data schließlich bezeichnet die Gesamtheit aller Daten, die von Unternehmen gesammelt werden, unabhängig von jeglicher Verarbeitung. Big Data ist ein eigenständiges Thema in unserer Informationsgesellschaft: Wir generieren immer vielfältigere Daten in immer größeren Mengen und mit immer höherer Geschwindigkeit. Der wahre Mehrwert für Unternehmen besteht darin, aus dieser Datenmasse nützliche Informationen zu gewinnen. Genau darin besteht die Aufgabe unseres Datahub-Teams: Wir implementieren eine Lösung, die in der Lage ist, einen großen Datenstrom zu bewältigen, sie in nützliche Informationen und Wissen umzuwandeln (z. B. durch Querverweise) und sie für die Abteilungen, die sie benötigen, zugänglich und nutzbar zu machen.
Kannst du uns erklären, worin genau deine Aufgabe im Datahub-Team besteht?
Als BI- Programmanalytiker besteht meine Hauptaufgabe darin, Lösungen zu bestimmen und zu entwickeln, die Rohdaten, die aus Informationssystemen oder Sensoren in Halb- und/oder Echtzeit stammen, in Informationen umwandeln, die für das Geschäft nützlich und klar sind. Ich stelle Berichte oder „Dashboards“ für die Abteilungen zur Verfügung, die es ihnen ermöglichen, auf Informationen zuzugreifen und sie besser zu interpretieren, indem sie sie beispielsweise mit anderen Elementen verknüpfen. Ich werde Ihnen später ein Beispiel nennen.
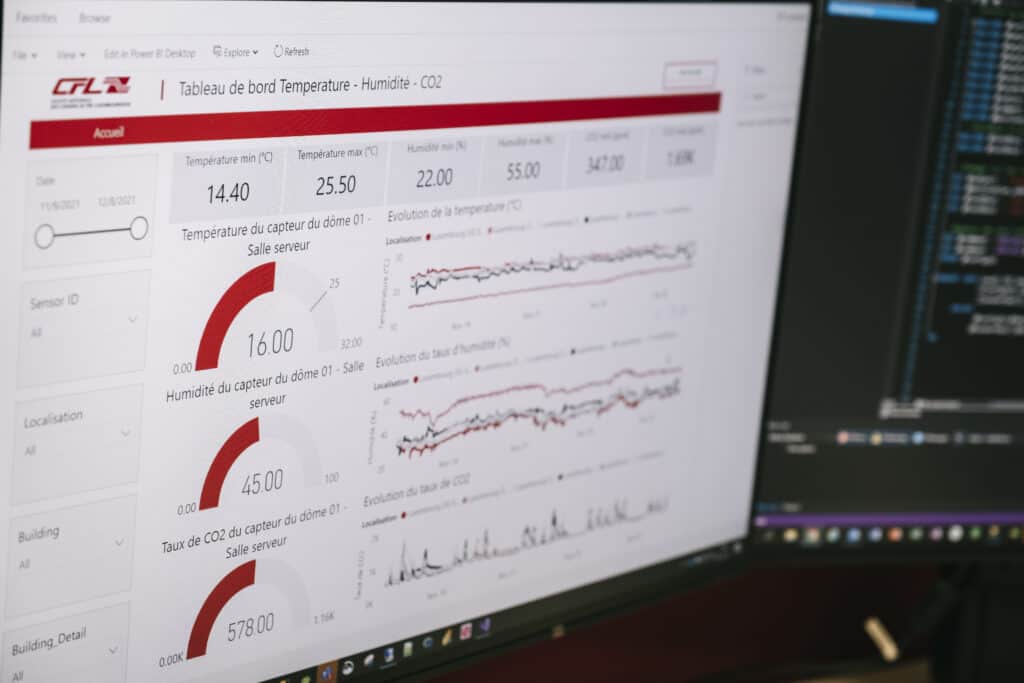
Seit zwei Jahren konzentrieren wir uns zudem auf eine neue Technologie, die es ermöglicht, Rohdaten diesmal in Echtzeit zu verarbeiten. Dafür arbeiten wir mit dem Internet Of Things-Team zusammen, um Betriebsabläufe aufzubauen, die Daten von den durch sie installierten Sensoren (in Räumen, an Bord von Schienenfahrzeugen, auf den Schienen …) abrufen und daraus mithilfe eines automatisierten Prozesses Informationen gewinnen.

Wie werden diese Berichte konzipiert?
Die Berichte werden ausgehend von den Bedürfnissen der Nutzer erstellt: Zunächst ermitteln wir die Quellen (intern oder extern), die uns die Daten liefern werden.
Wenn es notwendig ist, sich mit einem externen System zu verbinden, um die Daten abzurufen, werden wir das IT-Sicherheitsteam einschalten, um sicherzustellen, dass die Datenströme vertraulich sind. Wie bei allem bei der CFL hat die Sicherheit oberste Priorität.
Bei intern gesammelten Daten kann es auch vorkommen, dass es sich um Daten handelt, die man noch nicht sammelt, und dann muss man festlegen, wie sie gesammelt werden sollen. In letzter Zeit läuft das meist über das IoT-Team und die Sensoren, die es installieren wird, um den Bedarf an Datenerhebung zu decken.
Sobald die Kommunikation zwischen all unseren Datenquellen und unserem Business-Intelligence-Tool funktioniert, analysieren wir als Nächstes, wie wir die Daten präsentieren oder miteinander verknüpfen können, damit sie zu nützlichen Informationen für den Nutzer werden.
Für die Nutzer bedeutet dies konkret, dass sie ins Internet gehen und sich in ihre digitale Arbeitsumgebung einloggen müssen, um auf ihren Bericht zuzugreifen, was sehr einfach ist. Die Informationen werden auf sehr visuelle Weise mit Tabellen, Grafiken und Histogrammen dargestellt, die verschiedene Kriterien aufgreifen, die sie nach Belieben anpassen können.

Wir haben Elisa aus dem IoT-Team vor einigen Monaten getroffen, und sie hat uns von dem intelligenten Parkplatz in Bettemburg erzählt. Sie wurde damit beauftragt, den richtigen Sensortyp zu finden, um die Anwesenheit von Autos auf dem Parkplatz zu erkennen. Worum geht es bei diesem Projekt von deinem Standpunkt aus?
Sobald das Team von Elisa den richtigen Sensortyp gefunden und sichergestellt hatte, dass er mit unserer Plattform kommunizierte, übernahm ich die Aufgabe, einen computergestützten Workflow einzurichten, der diese Daten abrief, in das gewünschte Format umwandelte und in unseren Datenbanken speicherte. Mithilfe eines anderen Teams der IT-Abteilung extrahierten wir die Daten, um sie den Nutzern intern zur Verfügung zu stellen. Das Ziel dieses Projekts ist es, den Zugbenutzern in Echtzeit Informationen über die Anzahl der verfügbaren Plätze zu liefern, damit sie ihre Reisen besser planen können. In einer nicht allzu fernen Zukunft möchten wir die Bewegungen auf dem Parkplatz genau vorhersagen können, immer mit dem Ziel, dem Kunden einen besseren Service zu bieten. Dazu werden wir uns auf die Historie der beobachteten Bewegungen stützen, um ein Vorhersagemodell zu erstellen. Anhand der in Echtzeit erhaltenen Informationen können wir dann die Auslastung des Parkplatzes in den nächsten Stunden vorhersagen.
Das wird noch eine Weile dauern, da es eine sehr hohe Expertise in Bezug auf die Wahl des für den Ansatz zu bevorzugenden mathematischen Modells erfordert. Wir lassen uns von einer externen Firma unterstützen, um Fortschritte zu erzielen, aber die Idee ist, kompetente Profile einzustellen, um das Team mittelfristig zu verstärken.

Du hast gerade den Kundenservice als treibende Kraft in diesem Smart-Parking-Projekt genannt. Hast du ein weiteres kundenrelevantes Beispiel aus den Themen, die euch im Datahub derzeit beschäftigen?
Wir haben keinen direkten Einfluss auf den Zugverkehr, können aber Daten bereitstellen, die diesen Einfluss haben. So ermöglichen beispielsweise die Zähldaten der Fahrgäste in den Zügen eine Anpassung des Angebots an die tatsächliche Auslastung der Verkehrsmittel.
Diese Zählung stützt sich auf die Daten, die von Sensoren an den Außen- und Innentüren der Züge gemeldet werden, und sendet die Daten in Echtzeit an das System. Wir wissen bereits jetzt in Echtzeit, wie viele Fahrgäste ein bestimmter Zug hat, wie viele an den verschiedenen Bahnhöfen entlang der Strecke aus- und einsteigen. Wenn wir unsere Nutzung weiter ausbauen, können wir den Reisenden auf dem Bahnsteig anzeigen, an welcher Stelle sie in den Zug einsteigen müssen, um sich einen Sitzplatz zu sichern, was sich positiv auf ihr Reiseerlebnis auswirken kann.
Wenn wir unsere Nutzung weiter ausbauen, können wir den Reisenden auf dem Bahnsteig anzeigen, an welcher Stelle sie in den Zug einsteigen müssen, um sich einen Sitzplatz zu sichern, was sich positiv auf ihr Reiseerlebnis auswirken kann.

Ein weiteres Projekt wird die Zuverlässigkeit unserer Züge und damit die Zufriedenheit der Reisenden beeinflussen: Es ist geplant, zahlreiche Daten im Zusammenhang mit dem rollenden Material (Zustand der Bremsen, Motoren, Temperatur…) zu sammeln, um Prinzipien des „Machine Learning“ zu integrieren und Wartungen effizienter zu antizipieren und Beschädigungen zu vermeiden. Dies wird die Ausfallzeiten unseres Materials verkürzen und schwere Pannen vermeiden, die in der Regel zu Verspätungen oder Ausfällen führen.

Verstehe ich dich also richtig, wenn du von „Machine Learning“ sprichst, dann sammelt man die Daten für eine gewisse Zeit und analysiert parallel dazu die Alterung und das Verhalten des Materials?
Ganz genau! Derzeit basieren die Wartungspläne für das rollende Material auf Zyklen von X Wochen. Mithilfe von Machine Learning würde man dann auf der Grundlage des tatsächlichen Zustands des Materials planen, was viel effizienter wäre und unsere Zuverlässigkeit deutlich erhöhen würde.
Die größte Herausforderung für uns ist es, jederzeit zuverlässige und relevante Informationen zu liefern, da die Erwartungen intern und extern natürlich steigen werden: Es liegt an uns, diesen Erwartungen gerecht zu werden.
Wie wird dein Beruf in 10 Jahren aussehen?
Keine Ahnung! Die Technologien entwickeln sich so schnell, dass es unmöglich ist, das zu sagen. Im Moment sind wir uns der reinen Statistik sicher, wir gleiten langsam in Richtung prädiktive Datenanalyse, und es wird dann ziemlich logisch in 3 bis 5 Jahren präskriptive Analyse sein, aber dann…?
Ich weiß nicht, wie mein Beruf in zehn Jahren aussehen wird, aber ich weiß, dass ich ihn weiterhin so ausrichten werde, dass sich der öffentliche Nahverkehr in Kombination mit geteilten Verkehrsmitteln – z. B. Fahrräder der Stadt oder Flex-Autos – auf natürliche Weise gegenüber dem Individualverkehr durchsetzen wird. Hierbei geht es um eine echte Umweltangelegenheit.
(…) ich weiß, dass ich ihn weiterhin so ausrichten werde, dass sich der öffentliche Nahverkehr in Kombination mit geteilten Verkehrsmitteln, (…) auf natürliche Weise gegenüber dem Individualverkehr durchsetzen wird. Hierbei geht es um eine echte Umweltangelegenheit.

Wenn Sie wie Thibaut mit dem Tempo der Digitalisierung Schritt halten und Ihrer Karriere einen Sinn geben wollen, kommen Sie zur CFL: Wir stellen ein.


Comments are closed.